Introduction
Last time, we discussed about how AI is now able to generate images with diffusion. It was truly an amazing idea! This time, I wanted to introduce more fun use case of these diffusion models.
As diffusion models went through more revolution, we were able to get more precise editing that is desired. Let’s take a look at the images below:

Image Reference Github: fondant-usecase

Applications
We can see how it can be used for interior design preview, or even virtual fitting, by specifying the region or purpose. In this case of virtual fitting, it will be changing the clothes of the model. This means that there is also potential to have some “personalized virtual fitting” where a user can provide their avatar or image to get a preview on how the clothes would fit on their body. The drawback of online shopping compared to offline shopping was that customers do not know if the clothes would fit them. These technology would be able to solve this limitation of online shopping.
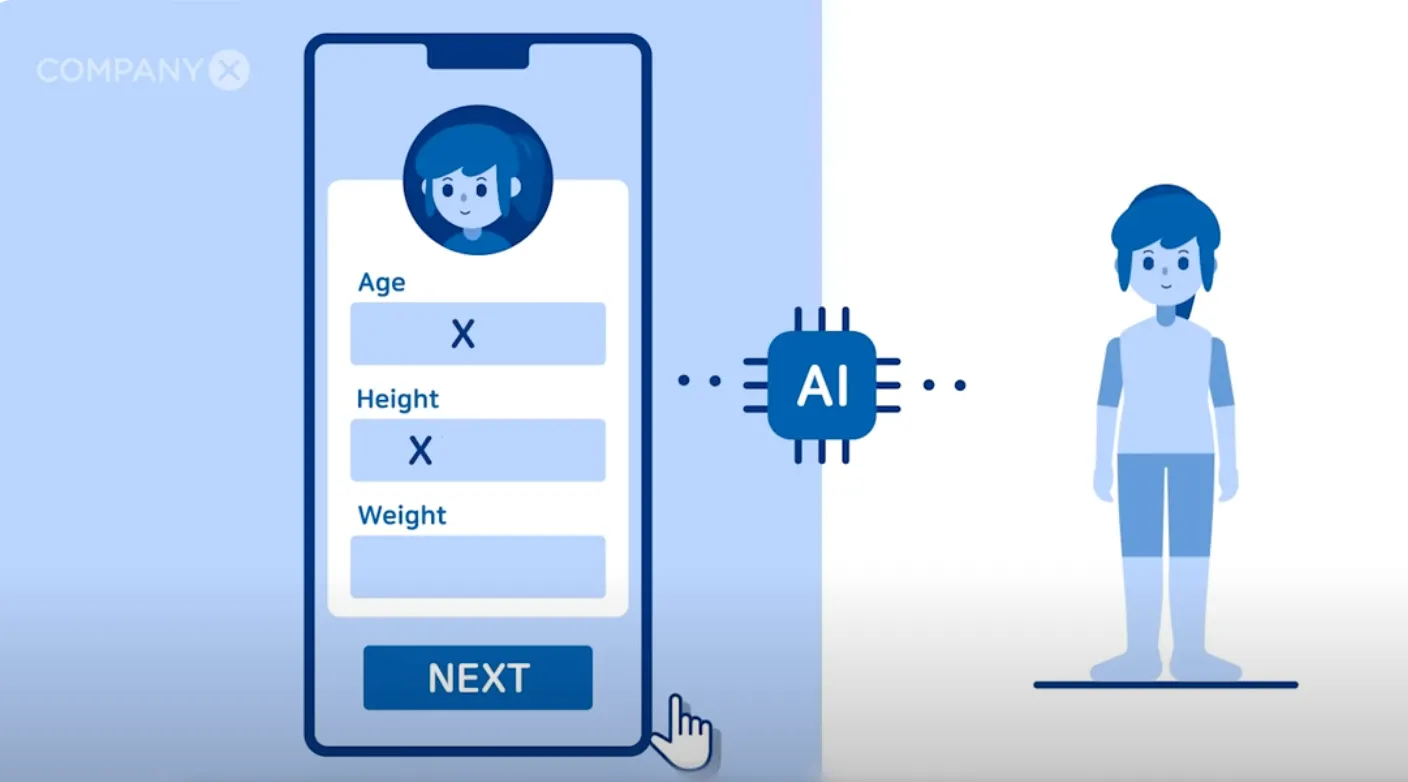
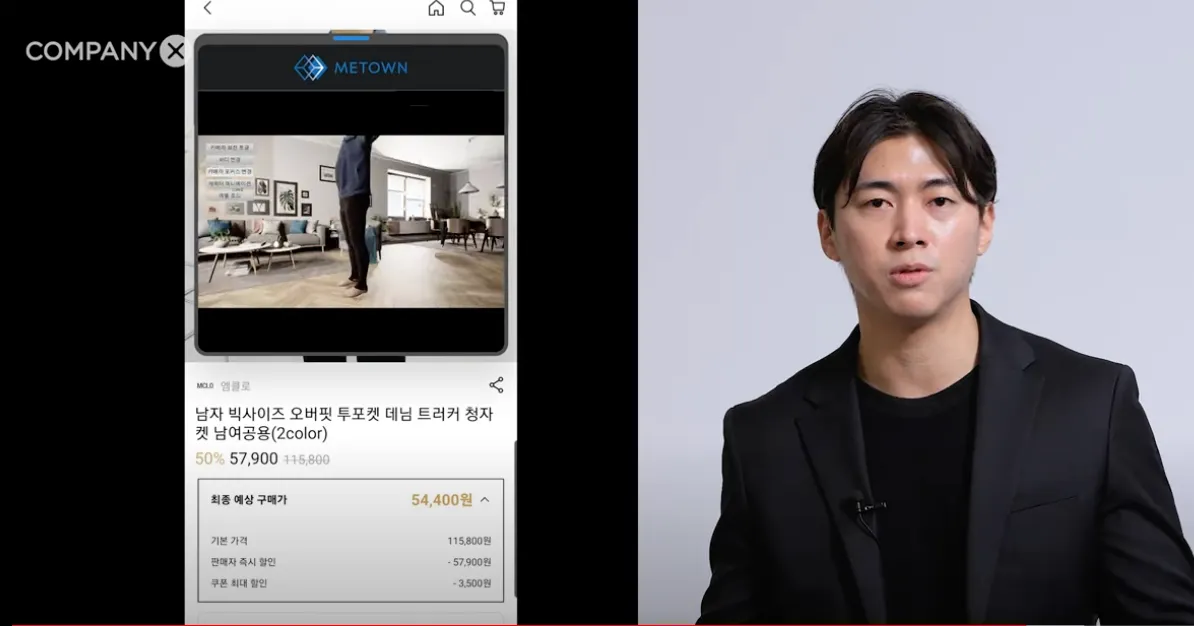
Metown is also trying to solve this problem with 3D virtual fitting (But this technology will be a discussion for next time).
Paper and Model Overview
Thus, the paper we will review today is “Control Net: Adding Conditional Control to Text-to-Image Diffusion Models”.
As we can infer from the title, this work allows us to “control” the diffusion image generation. This further allows us to make what we just saw previously available. This model specialized the previous work of stable diffusion. We now achieve freedom and take “control” of the image modification, and give more inputs than initial text prompt.
This is the key motivation and the gist of this work.

This is super cool! Now let’s dig into the paper!
Model Architecture
“2023/0/14 - released ControlNet 1.1.”
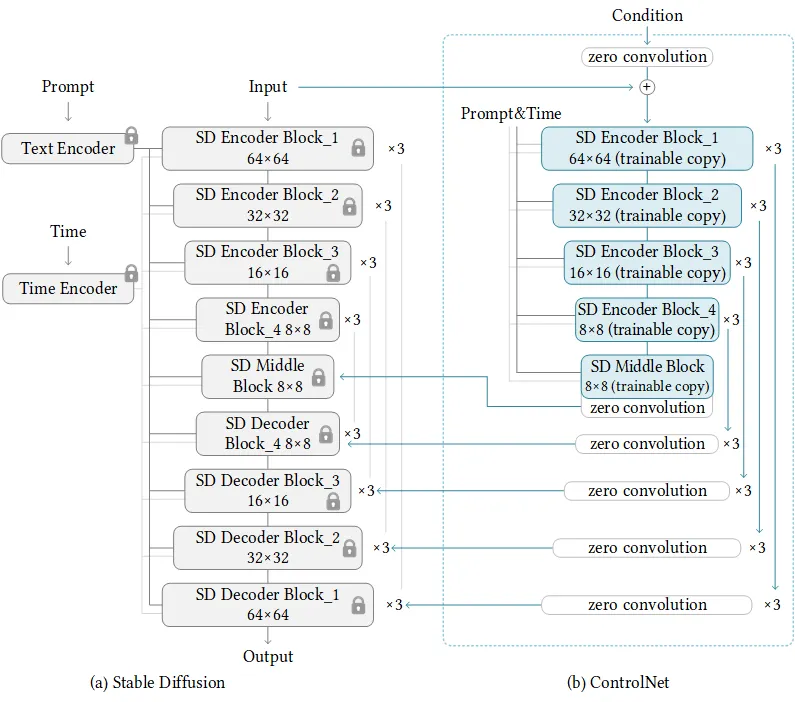
If we see the architecture of the ControlNet model, we notice that it freezes the original stable diffusion model. Then, there is an external network that allows some modification or additional information to be incorporated in the main model.
Referencing the review/word of Koiboi (Youtube), this architecture design is related to hyper network, where we have a sub model built on top of a pre-existing powerful model that is robust.
“HyperNetwork is an approach that originated in the Natural Language Processing (NLP) community [25], with the aim of training a small recurrent neural network to influence the weights of a larger one. It has been applied to image gener- ation with generative adversarial networks (GANs) [4, 18]. Heathen et al. [26] and Kurumuz [43] implement HyperNet- works for Stable Diffusion [72] to change the artistic style of its output images”
- page 2 of ControlNet
Brief Summary of Hypernetwork
“Hypernetwork is a fine-tuning technique developed by Novel AI, an early adopter of Stable Diffusion. It is a small neural network attached to a Stable Diffusion model to modify its style.”
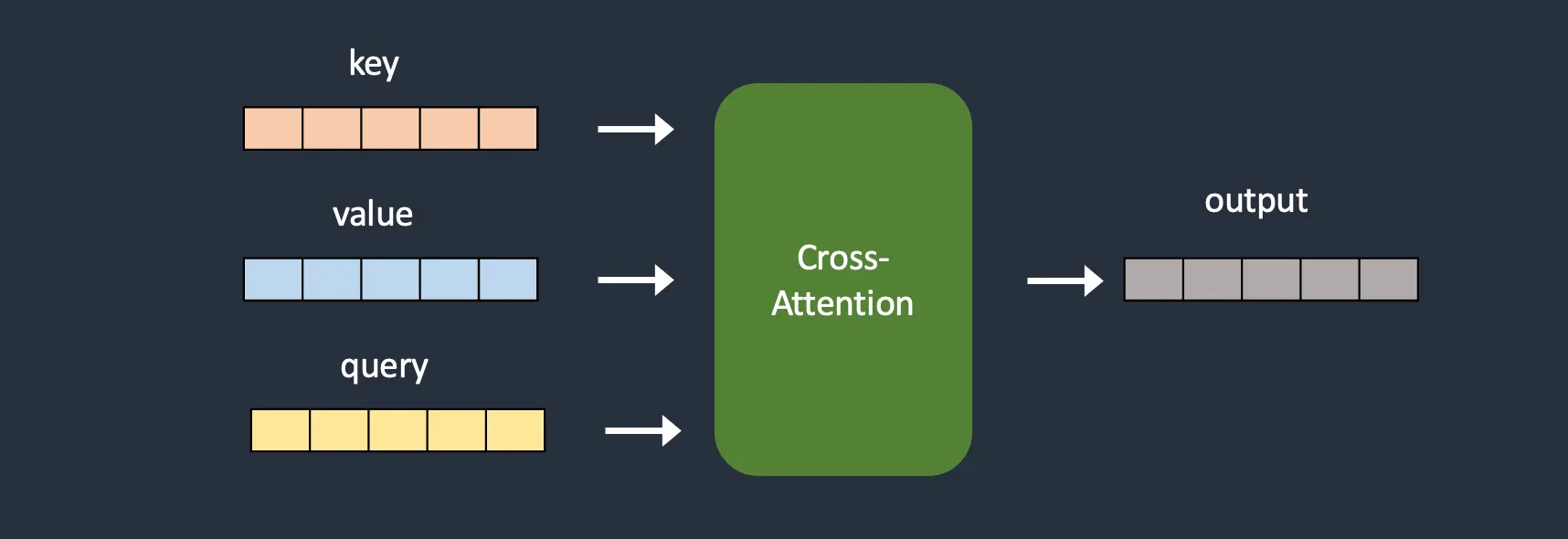
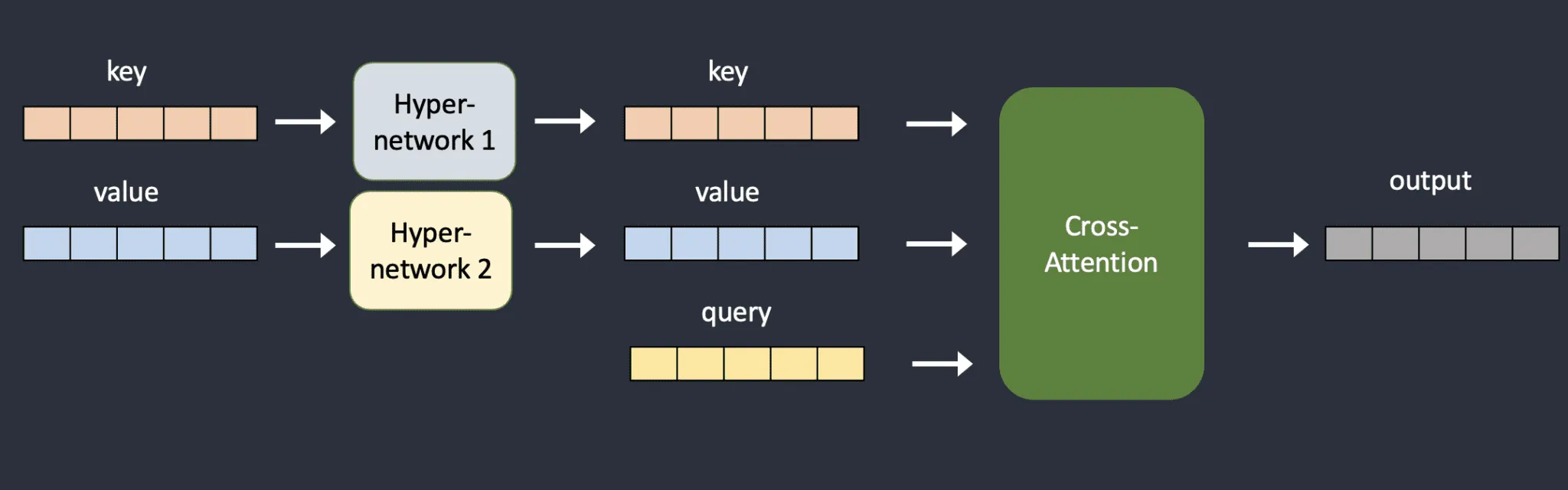
Above is the cross attention module in the stable diffusion model, while the below image is the Hypernetwork design where it adds an additional layer that modifies the keys and values.
Math Review
Compare to the previous papers that were heavily reliant on math, as this work was mainly focusing on incorporating this new idea of external network on stable diffusion, there isn't too much math derivations proposed in this work. Below are some main training mechanism and maths incorporated:
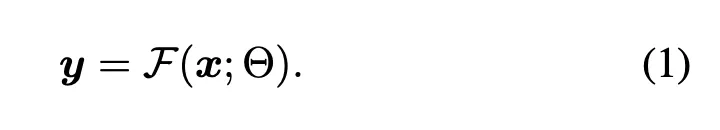
F(x;Θ) is the trained network with parameters Θ, that transforms an input feature map x, into another feature map y as described in the paper. In the context of image generation models, this input x and y will be in 2D feature map (h, w, c).
ControlNet Layer
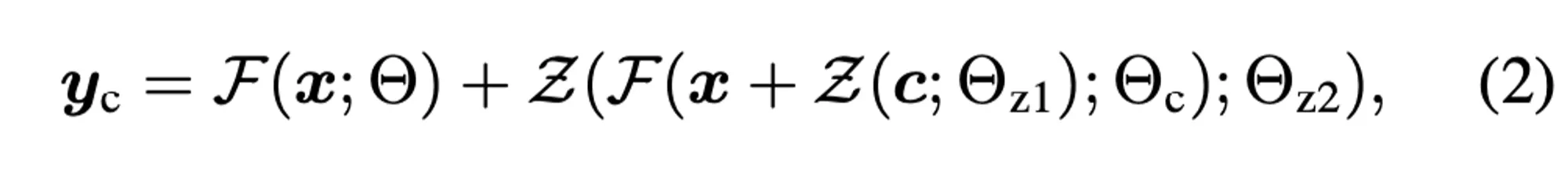
As noted previously, the key of ControlNet is adding an external network on top of frozen layer of stable diffusion. Θ notes the original parameter block parameter, while Θc is the cloned trainable parameter that is being added. The F(x;Θ) would denote the original stable diffusion model in this case.
Zero convolution layers, denoted as Z(⋅;⋅) in the paper are special 1 × 1 convolution layers where both the weight and bias are initialized to zeros. We can see that these two layers of zero convolution layer is added to the original stable diffusion model, creating the clone layer Yc. This is the output of ControlNet Block.
ControlNet Layer - Clone Layer

“In the first training step, since both the weight and bias parameters of a zero convolution layer are initialized to zero, both of the Z (·; ·) terms in Equation (2) evaluate to zero, and yc = y. In this way, harmful noise cannot influence the hidden states of the neural network layers in the trainable copy when the training starts”
Conditioning

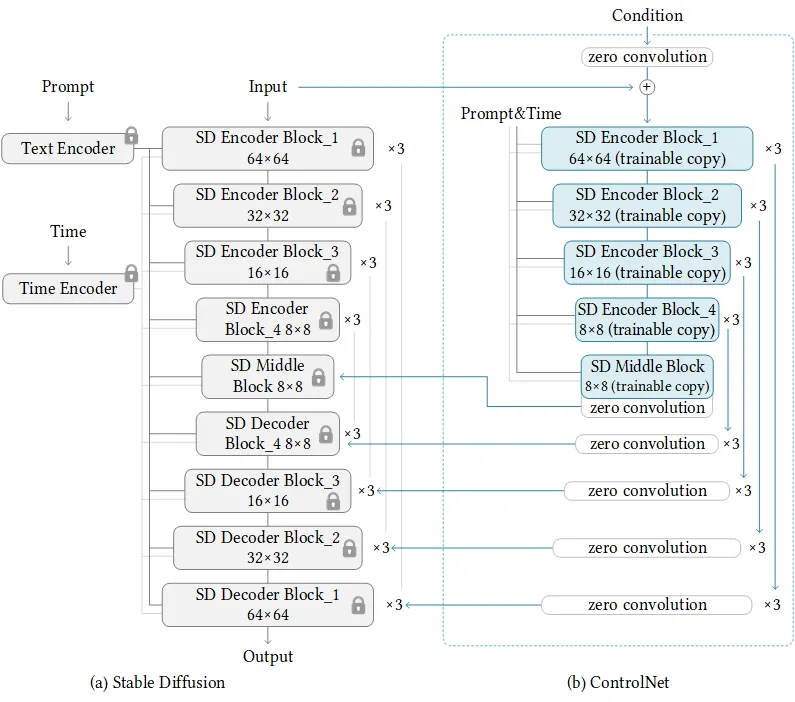
Revisiting the architecture, the author states that the ControlNet structure is applied to each encoder level of the U-net of the stable diffusion model. Specifically, “trainable copy of the 12 encoding blocks and 1 middle block of Stable Diffusion” is created.
To add this ControlNet layer to stable diffusion, the author “convert each input conditioning image (e.g., edge, pose, depth, etc.) from an input size of 512 × 512 into a 64 × 64 feature space vector that matches the size of Stable Diffusion.” This conditioning vector cf is what is denoted in equation (4).
These cf might be “various conditioning controls, e.g., edges, depth, segmentation, human pose, etc”
Additional Note:
E(·): tiny network of four convolution layers with 4 × 4 kernels and 2 × 2 strides (activated by ReLU, using 16, 32, 64, 128, channels respectively, initialized with Gaussian weights and trained jointly with the full model
Training
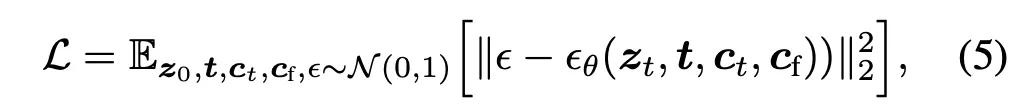
z0: image input
zt: noisy-input
t: time step
ct: text prompt (condition)
cf: task-specific condition
εθ: network predicting the noise added to the noisy image zt
Also, the author states that they randomly replaced 50% text prompt ct with empty strings to increase ControlNet’s ability to robustly recognize input condition images that serve as a replacement for the prompt.
This equation is just essentially minimizing the difference between the actual noise ε added to the original image z0 and the predicted noise from the network εθ.
Code Snippet
I took few snippets out of the official ControlNet implementation repo
class ControlledUnetModel(UNetModel):
def forward(self, x, timesteps=None, context=None, control=None, only_mid_control=False, **kwargs):
hs = []
with torch.no_grad():
t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False)
emb = self.time_embed(t_emb)
h = x.type(self.dtype)
for module in self.input_blocks:
h = module(h, emb, context)
hs.append(h)
h = self.middle_block(h, emb, context)
if control is not None:
h += control.pop()
for i, module in enumerate(self.output_blocks):
if only_mid_control or control is None:
h = torch.cat([h, hs.pop()], dim=1)
else:
h = torch.cat([h, hs.pop() + control.pop()], dim=1)
h = module(h, emb, context)
h = h.type(x.dtype)
return self.out(h)
JavaScript
복사
We notice the following:
input x: which wold be corresponding to the noisy input
t_emb: time step t is embedded with t_emb
middle block with context as a parameter (along with time embedding)
if control cf is provided (not None), they are included in the h block
class ControlLDM(LatentDiffusion):
def __init__(self, control_stage_config, control_key, only_mid_control, *args, **kwargs):
super().__init__(*args, **kwargs)
self.control_model = instantiate_from_config(control_stage_config)
self.control_key = control_key
self.only_mid_control = only_mid_control
self.control_scales = [1.0] * 13
...
def apply_model(self, x_noisy, t, cond, *args, **kwargs):
assert isinstance(cond, dict)
diffusion_model = self.model.diffusion_model
cond_txt = torch.cat(cond['c_crossattn'], 1)
if cond['c_concat'] is None:
eps = diffusion_model(x=x_noisy, timesteps=t, context=cond_txt, control=None, only_mid_control=self.only_mid_control)
else:
control = self.control_model(x=x_noisy, hint=torch.cat(cond['c_concat'], 1), timesteps=t, context=cond_txt)
control = [c * scale for c, scale in zip(control, self.control_scales)]
eps = diffusion_model(x=x_noisy, timesteps=t, context=cond_txt, control=control, only_mid_control=self.only_mid_control)
return eps
...
@torch.no_grad()
def sample_log(self, cond, batch_size, ddim, ddim_steps, **kwargs):
ddim_sampler = DDIMSampler(self)
b, c, h, w = cond["c_concat"][0].shape
shape = (self.channels, h // 8, w // 8)
samples, intermediates = ddim_sampler.sample(ddim_steps, batch_size, shape, cond, verbose=False, **kwargs)
return samples, intermediates
JavaScript
복사
class DDIMSampler(object):
def __init__(self, model, schedule="linear", **kwargs):
super().__init__()
self.model = model
self.ddpm_num_timesteps = model.num_timesteps
self.schedule = schedule
...
@torch.no_grad()
def p_sample_ddim(self, x, c, t, index, repeat_noise=False, use_original_steps=False, quantize_denoised=False,
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
unconditional_guidance_scale=1., unconditional_conditioning=None,
dynamic_threshold=None):
b, *_, device = *x.shape, x.device
if unconditional_conditioning is None or unconditional_guidance_scale == 1.:
model_output = self.model.apply_model(x, t, c)
...
# direction pointing to x_t
dir_xt = (1. - a_prev - sigma_t**2).sqrt() * e_t
noise = sigma_t * noise_like(x.shape, device, repeat_noise) * temperature
if noise_dropout > 0.:
noise = torch.nn.functional.dropout(noise, p=noise_dropout)
x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noise
return x_prev, pred_x0
JavaScript
복사
So from above, we see how self.control_model is loaded with the config file. Then, in the sample_log function, it generates diffusion samples that integrates the control_model with DDIM (Denoising Diffusion Implicit Models) sampler.
Conclusion
ControlNet allows us to achieve more freedom on controlling and modifying the diffusion models.
“Additionally, we report that the training of ControlNet is robust and scalable on datasets of different sizes, and that for some tasks like depth-to-image conditioning, training Con- trolNets on a single NVIDIA RTX 3090Ti GPU can achieve results competitive with industrial models trained on large computation clusters.”
- page 2 of ControlNet
Efficiency
Also, one thing I wanted to highlight again is the efficiency of this design. As the author states in this work it is also a very efficient way to achieve the goal of customizing the diffusion models. Since we are adding a external condition model on top of pre-trained stable diffusion layer that is locked, we would only have to train this external model rather than training the entire architecture on thousands of clusters again. In broad sense, it is basically fine-tuning the stable diffusion model for controllability.
Reviewed by Metown Corp. (Sangbin Jeon, PhD Researcher)
References and Further Readings:
